Hiveの体験
web 2017/12/17 by ishiage
こんにちは。
R&Dの石揚です。
今回はHadoopのMapReduceをSQLチックに使うことが出来るHiveの体験をやってみましょう!
通常Hadoopで処理するにはMapReduceを利用するのですが、このMapReduceというのは少し扱いにくい物で
なかなか手軽に扱える物ではありませんでした。
それを解消するために、RDBの様なSQLライクな使い方が出来るエコシステムがHiveです。
では早速試してみましょう!
まずは本体をダウンロードしましょう。
vagrant$ curl -L -O http://ftp.jaist.ac.jp/pub/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
本体を解凍
vagrant$ tar xzvf apache-hive-1.2.2-bin.tar.gz
パスを通しておきます
vagrant$ vi ~/.bashrc
export HIVE_HOME=/home/vagrant/apache-hive-1.2.2-bin
export PATH=$PATH:$HIVE_HOME/bin
vagrant$ source ~/.bashrc
これでひとまずhiveコマンドが使えるはずです。
試しにHiveを使ってみましょう。
vagrant$ hive
mysqlで実行したような対話型コンソールが開くと思います。
試しにデーターベースを作ってみましょう。
hive> create database test;
次にテーブル
hive> create table human(id int, name string, age int) row format delimited fields terminated by '\t';
データーを入れてみましょう。
ihive> insert into human values(1, 'suzuki', 25); ihive> insert into human values(2, 'tanaka', 33); ihive> insert into human values(3, 'yamamoto', 41);
Selectを使ってみましょう
hive> select * from human;
1 suzuki 25
2 tanaka 33
3 yamamoto 41
どうでしょう?
上のような結果は出たでしょうか?
ここまでは通常のDBの操作と変わりません。
では次にHDFSを利用しつつHiveを操作してみましょう。
tag : Hadoop Hive
Hadoopの体験
web 2017/10/21 by ishiage
今回は実際にHadoopをインストールしてHDFSとMapRedudeを体感してみましょう!
HDFSはHadoopで利用されるFS(ファイルシステム)です。
MapReduceとは分散処理されるプログラミングモデルです。
では早速動かしてみましょう!
vagrantでCentOS7の用意
(VagrantとVM環境(VirtualBox)などのインストールは用意しておいて下さい。ここで書くとそれだけで記事が終わってしまうので・・)
VagrantでCentOS7の準備
ディレクトリ作成
local$ mkdir hadoop local$ cd hadoop
centos7を追加
local$ vagrant box add centos/7
(その後利用しているvmを選択)
boxのダウンロードなどがあり時間がかかるので少し待ちましょう。
local$ vagrant init centos/7
centos7を起動
local$ vagrant up
どうやらWindows7だとVagrantのバージョンが1.97以降は動かないようです。
下記のWindows7の方は下記のURLからバージョン1.96をダウンロードしてインストールしましょう。
https://releases.hashicorp.com/vagrant/
vagrantでcentos7が立ち上がったあとはログインしてみましょう。
local$ vagrant ssh
ログインできれば問題無しです!
ログアウトしておきましょう。
local$ exit
Hadoopの準備
JDKのインストール
HadoopはJava製です。
なのでJavaのインストールが必要になります。
JDKをインストールしましょう。
http://www.oracle.com/technetwork/java/javase/downloads/index.html
JDKをダウンロード
Accept License Agreementをチェック
jdk-x_linux-x64_bin.rpmをクリック
おすすめは8系。9系は色々とエラーが出るので・・。
scpでファイルを送るためにssh.configをvagrant用ssh.confgを作成
local$ vagrant ssh-config > ssh.config
jdkのrpmをvagrant側にコピー
local$ scp -F ssh.config jdk-x_linux-x64_bin.rpm vagrant@default:~/
vm上のCentOS7にログイン
local$ vagrant ssh
vagrant sshでログインしJDKをインストール
vagrant$ sudo rpm -ivh jdk-8xxxx_linux-x64_bin.rpm
Hadoopインストール
http://ftp.jaist.ac.jp/pub/apache/hadoop/common/
からダウンロード
vagrant$ curl -L -O http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz vagrant$ tar xzvf hadoop-2.8.3.tar.gz
Hadoop設定
とりあえず最低限の動作で動かしてみます。
Hadoopの動作に必要な設定ファイルを編集します。
vagrant$ vi hadoop-*/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
HDFSの設定をします。
vagrant$ vi hadoop-*/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/vagrant/var/lib/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/vagrant/var/lib/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
環境設定を設定しましょう。
vagrant$ vi .bashrc
export JAVA_HOME=/usr/java/default export HADOOP_HOME=/home/vagrant/hadoop-2.8.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
現在のコンソールで反映
vagrant$ source .bashrc
Hadoopを動かす場合、動かすユーザーはパスワード無しでのsshログインが必要となるので、
パスワード無しの公開鍵を作成します。
vagrant$ ssh-keygen
Enter file in which to save the key (/home/vagrant/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/vagrant/.ssh/id_rsa. Your public key has been saved in /home/vagrant/.ssh/id_rsa.pub. The key fingerprint is: SHA256:j6R5DKw4CodWaBn87FUibtnRkwsAcNaDH+5IgliBH6w vagrant@localhost.localdomain The key's randomart image is:
そのままエンターを3回押してパスワード無しの公開鍵を作成
鍵の設置
vagrant$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
一度ログインしておきます。
vagrant$ ssh localhost
yesと押してそのまま進む。
HDFSのフォーマット
vagrant$ hdfs namenode -format
そしてhadoopを起動。
vagrant$ start-all.sh
このコマンドだけで各サービスが自動的に立ち上がります。
ちなみに止めるときは
vagrant$ stop-all.sh
HDFSとMapReduceの体験
HDFS編
では次にHDFSを使ってみましょう。
まずはローカルに適当なファイルを用意しそのファイルをHDFS上に置きます。
vagrant$ touch data vagrant$ vi data
この後英単語のカウントを行うので英語で適当に書いて下さい。どっかのサイトのコピーでも!
用意が終わったらhadoopコマンドでHDFSにファイルを置きます
vagrant$ hadoop fs -put data /
置き終わったら、ファイルの確認をしましょう。
vagrant$ hadoop fs -ls /data
ついでに中身も見てみましょう
vagrant$ hadoop fs -cat /data
ではこのdataファイルをもう一度Linuxのローカル上に持ってきてみましょう
vagrant$ hadoop fs -get /data ./data.txt
ファイルを見るとdataとdata.txtは同じ物だと思います。
HDFSは基本的にこのようにファイルのやりとりを行います。
Linux上のFSと比べて反応が遅く使い勝手もいまいちですよね・・。
一般的なFSと比べて使いづらいものの、HDFSはHadoopに最適化されておりHadoop上では非常に良いパフォーマンスを出してくれます。
MapReduce編
では次にMapReduceを試してみましょう。
今回は先ほどのdataファイルを利用して単語のカウントを行います。
MapReduceでプログラミングしたい所ですが、それだけでまた記事が終わってしまうので、
今回はHadoopが用意しているプログラムを利用します。
vagrant$ hadoop jar hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /data /result
おそらくいろいろなログがでて来るかと思います。
最終的にHDFS上の/resultに結果ファイルが出来ます。
では結果を見てみましょう。
vagrant$ hadoop fs -cat /result/*
ズラズラと出て分かりづらいのでファイルで落としましょう。
vagrant$ hadoop fs -cat /result/* > result vagrant$ vi result
終わりに
これでHDFSとMapReduceの体験は終わりです。
いかがだったでしょうか?
Hadoopはバッチ処理として利用することが多いので、通常のバッチ作成と比べると非常に面倒くさいですね。
ただこのシステムを使い、ノードを増やすことにより非常に大きなデータでも通常のバッチとは比べものにならないほどの
速い処理を行ってくれます。
今回はお試しだったのでMapReduceのプログラミングを行いませんでしたが、正直MapReduceのプログラミングは面倒くさいです。
正直言うと私も殆どMapReduceでのプログラミングは書いたことありません。
ではどうやって動かすかというとHiveというSQL形式でジョブが動かせるエコシステムを使っています。
次回はこのHiveの動かし方を紹介しようと思います。
そのため引き続きこのVagrantの環境を利用しようと思うので、消さずにそのままお使い下さい!
tag : Hadoop HDFS MapReduce
Hadoopとは
web 2017/09/15 by ishiage
こんにちは!
こんにちは!クラヴィスR&Dエンジニアの石揚です。
皆さんHadoopを知っていますか?
私は現在Hadoop(商用版)の担当をしており、日々構築運用&集計の業務をおこなっています。
ある程度は詳しいということで、少しHadoopについてまとめたいと思います。
多少細かいところははしおって、なるべく分かりやすく説明しようと思います。
大規模分散について
Hadoopとは大規模分散システムを実現させるためのミドルウェアのことです。
まず大規模分散システムとは何でしょう?
通常バッチはPerlやPythonなどの言語を使い処理自体は1台のサーバーで済ませることが多いと思います。
処理が単純でデータが小さい場合であれば処理時間は現実的な時間で終わることが良いのですが、
処理が複雑でデータが非常に大きいと・・・1台では現実的な時間では終わらないことがあります。
もちろん処理時間を縮めたい場合ハードウェアの性能を上げる(CPUの性能を上げたりメモリを増やしたりなど)
スケールアップをすれば問題か解決することもあります。
ただそれを行ったとしてもマシンスペックというのはお金を2倍かければ性能が2倍というような比例して上がるわけでもなく、
そもそもマシン1台当たりのスペックにも限界があります。
(例えば1GBのデータを処理するのに1時間かかったとして1TBでは・・約41日・・。処理を2倍にしても約20日・・。さらにデータ量が増えると・・)
ではどう解決するかと言うと、単純にマシンの台数を増やし処理を分散させるという方法があります。スケールアウトですね。
台数を増やすのであれば、予算が許す限り性能はいくらでも上げられることが出来ます。*1
しかし残念なことにハードウェアをスケールアウトしプログラムを作る場合・・次はプログラム側が非常に複雑になってしまいます。
汎用的な物となると尚更複雑になってしまいます。
ハードウェアで解決するものの次はソフトウェア側でコストがあまりにもかかり結局実現が難しい問題になります・・・
っが!
それを解決するためのソフトウェアがまさにHadoopなのです!
*1:厳密にはスケールアウトも上限はあるものの、スケールアップより圧倒的に上限は上です。
Hadoopのバージョンによる違い
さてそのHadoopですが、現在バージョンの違いにより大きく二つに分けることが出来ます。
YARNに対応したHadoop(2系)とYARNに対応していない旧Hadoop(1系)です。
旧Hadoop(バージョン1系)
まずは旧Hadoopについて。
そもそもHadoopにはMapReduceというプログラミングモデルとHDFSというファイルシステム二つを合わせてHadoopと言っていました。MapReduceとはプログラミングモデルなのですが、詳しく説明すると長くなってしまうので簡単に説明しますが、MapとReduceというプログラムを作成する必要があります。分散処理のプログラミングは非常に複雑なので、そのプログラミングを書くよりは簡単・・・とはいえMapReduceの概念も少し複雑ではあります。
HDFSというファイルシステムも一般的なファイルシステムとだいぶ違い、様々な制約があります。

現在のHadoop(バージョン2系)
そして現在のHadoopですが、旧との大きな違いはMapReduceとHDFSだけのシステムではなく
エコシステムを含めた大規模分散の総合的なシステムという所です。*2
特にYARNの対応が大きな違いの一つです。
*2:ただ旧Hadoopでもその他のエコシステムは問題なく使えていた。若干分かりづらい所・・。
YARNとは
YARNとはハードウェアのリソースを管理するシステムです。
管理するリソースの対象はCPUのコア数やメモリの容量などです。
旧HadoopではMapReduce側のシステム(JobTrackerやTaskTracker)がスロットという概念でリソースを使っていました。
旧Hadoopのリソースの使い方としてスケジューラなどを設定しない場合全てのリソースを使い切り、かつその他のエコスステムのリソースの利用はそれぞれ独立だったので、非常に効率の悪いリソースの使い方をしていました。
YARNはCPUのコア数とメモリの容量を各エコシステムに対して要求されたリソースを管理し、
コンテナという概念で効率良く複数のエコシステムが問題無く動く働きをしてくれます。
例 :
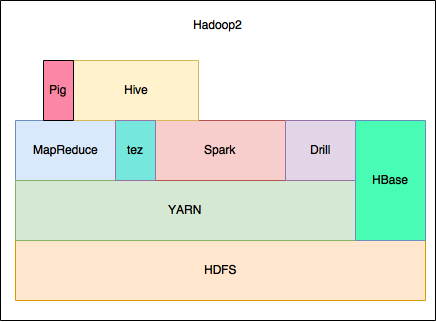
様々なエコシステム
Hadoopには様々なエコシステムがあります。
Spark, Impala, Drill, Hbase, Hive, Zookeeper etc…
それぞれ一つづつ説明したいところですが、膨大な量になりそうなのでここでは辞めておきます・・。
現在のHadoopは様々なエコシステムを含めた総合的な分散処理をシステムとなっています。
Hadoopの由来
ちなみにHadoopの由来はHadoopの産みの親であるダグカッティングさんのお子さんが象さんのぬいぐるみに付けていた名前だそうです。
ただ象さんの色が黄色なのは謎です。

tag : Hadoop YARN
