Hadoopとは
web 2017/09/15 by ishiage
こんにちは!
こんにちは!クラヴィスR&Dエンジニアの石揚です。
皆さんHadoopを知っていますか?
私は現在Hadoop(商用版)の担当をしており、日々構築運用&集計の業務をおこなっています。
ある程度は詳しいということで、少しHadoopについてまとめたいと思います。
多少細かいところははしおって、なるべく分かりやすく説明しようと思います。
大規模分散について
Hadoopとは大規模分散システムを実現させるためのミドルウェアのことです。
まず大規模分散システムとは何でしょう?
通常バッチはPerlやPythonなどの言語を使い処理自体は1台のサーバーで済ませることが多いと思います。
処理が単純でデータが小さい場合であれば処理時間は現実的な時間で終わることが良いのですが、
処理が複雑でデータが非常に大きいと・・・1台では現実的な時間では終わらないことがあります。
もちろん処理時間を縮めたい場合ハードウェアの性能を上げる(CPUの性能を上げたりメモリを増やしたりなど)
スケールアップをすれば問題か解決することもあります。
ただそれを行ったとしてもマシンスペックというのはお金を2倍かければ性能が2倍というような比例して上がるわけでもなく、
そもそもマシン1台当たりのスペックにも限界があります。
(例えば1GBのデータを処理するのに1時間かかったとして1TBでは・・約41日・・。処理を2倍にしても約20日・・。さらにデータ量が増えると・・)
ではどう解決するかと言うと、単純にマシンの台数を増やし処理を分散させるという方法があります。スケールアウトですね。
台数を増やすのであれば、予算が許す限り性能はいくらでも上げられることが出来ます。*1
しかし残念なことにハードウェアをスケールアウトしプログラムを作る場合・・次はプログラム側が非常に複雑になってしまいます。
汎用的な物となると尚更複雑になってしまいます。
ハードウェアで解決するものの次はソフトウェア側でコストがあまりにもかかり結局実現が難しい問題になります・・・
っが!
それを解決するためのソフトウェアがまさにHadoopなのです!
*1:厳密にはスケールアウトも上限はあるものの、スケールアップより圧倒的に上限は上です。
Hadoopのバージョンによる違い
さてそのHadoopですが、現在バージョンの違いにより大きく二つに分けることが出来ます。
YARNに対応したHadoop(2系)とYARNに対応していない旧Hadoop(1系)です。
旧Hadoop(バージョン1系)
まずは旧Hadoopについて。
そもそもHadoopにはMapReduceというプログラミングモデルとHDFSというファイルシステム二つを合わせてHadoopと言っていました。MapReduceとはプログラミングモデルなのですが、詳しく説明すると長くなってしまうので簡単に説明しますが、MapとReduceというプログラムを作成する必要があります。分散処理のプログラミングは非常に複雑なので、そのプログラミングを書くよりは簡単・・・とはいえMapReduceの概念も少し複雑ではあります。
HDFSというファイルシステムも一般的なファイルシステムとだいぶ違い、様々な制約があります。

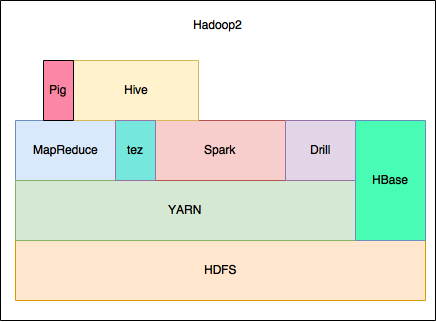
現在のHadoop(バージョン2系)
そして現在のHadoopですが、旧との大きな違いはMapReduceとHDFSだけのシステムではなく
エコシステムを含めた大規模分散の総合的なシステムという所です。*2
特にYARNの対応が大きな違いの一つです。
*2:ただ旧Hadoopでもその他のエコシステムは問題なく使えていた。若干分かりづらい所・・。
YARNとは
YARNとはハードウェアのリソースを管理するシステムです。
管理するリソースの対象はCPUのコア数やメモリの容量などです。
旧HadoopではMapReduce側のシステム(JobTrackerやTaskTracker)がスロットという概念でリソースを使っていました。
旧Hadoopのリソースの使い方としてスケジューラなどを設定しない場合全てのリソースを使い切り、かつその他のエコスステムのリソースの利用はそれぞれ独立だったので、非常に効率の悪いリソースの使い方をしていました。
YARNはCPUのコア数とメモリの容量を各エコシステムに対して要求されたリソースを管理し、
コンテナという概念で効率良く複数のエコシステムが問題無く動く働きをしてくれます。
例 :
様々なエコシステム
Hadoopには様々なエコシステムがあります。
Spark, Impala, Drill, Hbase, Hive, Zookeeper etc…
それぞれ一つづつ説明したいところですが、膨大な量になりそうなのでここでは辞めておきます・・。
現在のHadoopは様々なエコシステムを含めた総合的な分散処理をシステムとなっています。
Hadoopの由来
ちなみにHadoopの由来はHadoopの産みの親であるダグカッティングさんのお子さんが象さんのぬいぐるみに付けていた名前だそうです。
ただ象さんの色が黄色なのは謎です。

tag : Hadoop YARN
